机器人训练
Search documents
训练机器人方式对了吗?英伟达DreamZero双榜第一新反思
机器之心· 2026-03-03 09:08
Core Insights - NVIDIA's DreamZero model has achieved top rankings in two significant robotics benchmarks, RoboArena and MolmoSpaces, indicating its superior performance in robotic tasks [1][3]. Group 1: Model Overview - DreamZero is a "world-action model" that simultaneously predicts future video and robot actions, allowing robots to envision future scenarios before taking action [4][10]. - The model integrates action generation and video generation, providing richer supervisory signals that enhance learning about environmental dynamics [12][13]. Group 2: Benchmark Performance - RoboArena is a distributed real-world benchmark testing various robotic tasks based on natural language instructions, where DreamZero was trained on similar data, leading to its strong performance [16][20]. - MolmoSpaces is a new benchmark platform with high-fidelity physics simulation, where DreamZero also excelled, indicating its adaptability to diverse environments [19][20]. Group 3: Training Data and Model Architecture - DreamZero utilizes different training datasets, including DROID and AgiBot, with a focus on data distribution being crucial for performance, as evidenced by its superior results on AgiBot compared to pi-0.5 [23][25]. - The model architecture of DreamZero is significantly larger, with 14 billion parameters compared to pi-0.5's 3 billion, which contributes to its enhanced capabilities [28]. Group 4: Input and Contextual Understanding - DreamZero can process up to 8 frames of contextual input, allowing it to capture motion trends and state changes, while pi-0.5 is limited to single-frame inputs [29][30]. - This ability to analyze multiple frames enables DreamZero to better understand complex physical dynamics and improve decision-making in robotic tasks [30]. Group 5: Implications and Future Directions - The findings suggest that a large amount of training data may not be as critical as previously thought, especially if the data is well-aligned with the target tasks [36]. - Upcoming discussions and analyses on DreamZero are anticipated, indicating ongoing interest and research in this area [36].


消息人士:特斯拉计划在得克萨斯州工厂开始训练擎天柱机器人。
Xin Lang Cai Jing· 2026-01-24 09:37
Group 1 - Tesla plans to begin training its Optimus robot at its Texas factory [1]
智元购买数千小时机器人训练数据
Shang Hai Zheng Quan Bao· 2026-01-15 06:08
Group 1 - The Hubei Humanoid Robot Innovation Center has signed a data service agreement with Zhiyuan Innovation (Shanghai) Technology Co., Ltd., selling thousands of hours of humanoid robot training data for various actions such as picking up cups, grabbing plates, and folding clothes [1][5] - The training data is priced at several hundred yuan per hour, which is above the industry average, and the center will continue to supply data based on Zhiyuan's specific scene requirements [1][5] - The center has 23 high-fidelity training scenarios and can directly collect data if customer needs match [1][5] Group 2 - Data collection requires specialized training for data collectors, and the collected data undergoes manual review before being uploaded to the cloud for further processing [3] - Each data collector can train for 8 hours a day, resulting in approximately 3 hours of valid data collection, with thousands of hours needed for a robot to learn a simple action like "picking up a cup" [3][5] - The training data will be integrated into Zhiyuan's humanoid robots, potentially reducing model training cycles and improving efficiency by 50% for tasks like folding clothes [5] Group 3 - The Hubei Humanoid Robot Innovation Center, established in June 2025, has deployed over a hundred training robots and built 23 high-fidelity training scenarios, making it one of the largest and most diverse professional training platforms for humanoid robots in China [5]

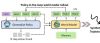
清华陈建宇团队× 斯坦福Chelsea课题组推出 Ctrl-World 可控世界模型,让机器人在想象中迭代
机器人大讲堂· 2025-10-30 10:18
Core Insights - The article discusses the breakthrough research "Ctrl-World," a controllable generative world model for robot manipulation developed by Chelsea Finn's team at Stanford University and Chen Jianyu's team at Tsinghua University, which significantly improves robot training efficiency and effectiveness [1][9][28]. Group 1: Research Background - The current challenges in robot training include high costs of strategy evaluation and insufficient data for strategy iteration, particularly in open-world scenarios [7][8]. - Traditional world models have limitations such as single-view predictions leading to hallucinations, imprecise action control, and poor long-term consistency [9][8]. Group 2: Ctrl-World Innovations - Ctrl-World introduces three key innovations: multi-view joint prediction, frame-level action control, and pose-conditioned memory retrieval, addressing the limitations of traditional models [9][11][15]. - The model uses multi-view inputs to reduce hallucination rates and improve accuracy in predicting robot interactions with objects [13][14]. - Frame-level action control ensures that visual predictions are tightly aligned with the robot's actions, allowing for centimeter-level precision [15][16]. - Pose-conditioned memory retrieval stabilizes long-term predictions, enabling coherent trajectory generation over extended periods [17][18]. Group 3: Experimental Validation - Experiments on the DROID robot platform demonstrated that Ctrl-World outperforms traditional models across multiple metrics, including PSNR, SSIM, and FVD, indicating superior visual fidelity and temporal coherence [20][21]. - The model's ability to adapt to unseen camera layouts showcases its generalization capabilities [22]. - Virtual evaluations of strategy performance closely align with real-world outcomes, significantly reducing evaluation time from weeks to hours [24][26]. Group 4: Strategy Optimization - Ctrl-World enables the generation of virtual trajectories that improve real-world strategy performance, achieving an average success rate increase from 38.7% to 83.4% without consuming physical resources [27][26]. - The optimization process involves virtual exploration, data selection, and supervised fine-tuning, leading to substantial improvements in task success rates across various scenarios [26][27]. Group 5: Future Directions - Despite its achievements, Ctrl-World has room for improvement, particularly in adapting to complex physical scenarios and reducing sensitivity to initial observations [28]. - Future plans include integrating video generation with reinforcement learning and expanding the training dataset to enhance model adaptability to extreme environments [28].
VR老师手把手教学!百台机器人排队等“入职”
Yang Shi Xin Wen Ke Hu Duan· 2025-10-22 07:26
Core Insights - The largest humanoid robot training center in China has officially opened in Beijing, preparing for the future large-scale application of humanoid robots [1] Group 1: Training Center Overview - The training center spans 14,000 square meters and is designed to replicate real-life work scenarios in a 1:1 scale [3] - Humanoid robots can choose from 16 specialized fields, including industrial intelligence, life services, and smart healthcare [1] Group 2: Training Environment and Methodology - The training environment includes various life service scenarios such as supermarket shelves, delivery lockers, and furniture, allowing robots to learn tasks like folding clothes and retrieving items [5] - The industrial manufacturing section features setups like electronic product assembly lines and automotive production workshops [7] - Each robot is assigned two instructors who utilize VR equipment and motion capture suits to enhance the training process [7] Group 3: Training Outcomes - Currently, nearly 100 robots in the center have mastered over 20 skills, including handling, inspection, and delivery, with a success rate exceeding 95% [9] - There is a growing demand for life service courses as potential employers are eager to hire these trained robots, indicating a closer step towards having robotic assistants in daily life [9]

仅看视频就能copy人类动作,宇树G1分分钟掌握100+,UC伯克利提出机器人训练新方式
量子位· 2025-05-08 04:04
Core Viewpoint - The article discusses the development of a new robotic training system called VideoMimic by a team from UC Berkeley, which allows robots to learn human movements from video without the need for motion capture technology [1][2]. Group 1: VideoMimic System Overview - VideoMimic has successfully enabled the Yushun G1 robot to mimic over 100 human actions [2]. - The core principle of VideoMimic involves extracting pose and point cloud data from videos, training in a simulated environment, and ultimately transferring the learned actions to a physical robot [3][17]. - The system has garnered significant attention online, with comparisons made to characters like Jack Sparrow from "Pirates of the Caribbean" [4]. Group 2: Training Process - The research team collected a dataset of 123 video clips filmed in everyday environments, showcasing various human movement skills and scenarios [5][6]. - The Yushun Go1 robot has been trained to adapt to different terrains and perform actions such as stepping over curbs and descending stairs, demonstrating its ability to maintain balance even when slipping [7][14][16]. Group 3: Technical Workflow - VideoMimic's workflow consists of three main steps: converting video to a simulation environment, training control strategies in simulation, and validating these strategies on real robots [18]. - The first step involves reconstructing human motion and scene geometry from single RGB videos, optimizing for accurate alignment of human movements and scene geometry [19]. - The second step processes the scene point cloud into a lightweight triangular mesh model for efficient collision detection and rendering [21]. Group 4: Strategy Training and Deployment - The training process is divided into four progressive stages, resulting in a robust control strategy that requires only the robot's proprioceptive information and local height maps as input [24]. - The Yushun Go1 robot, equipped with 12 degrees of freedom and various sensors, serves as the physical testing platform for deploying the trained strategies [30][31]. - The deployment involves configuring the robot's PD controller to match the simulation environment and utilizing real-time data from its depth camera and IMU for effective movement [35][39]. Group 5: Research Team - The project features four co-authors, all PhD students at UC Berkeley, with diverse research interests in robotics, computer vision, and machine learning [43][48][52].

谷歌DeepMind CEO展示Genie 2:机器人训练新时代
Sou Hu Cai Jing· 2025-04-22 02:24
Core Insights - Google DeepMind has made a significant breakthrough with its AI model Genie 2, showcasing its potential in robot training [1][3] - Genie 2 can generate interactive 3D environments from a single static image, providing realistic simulation for AI agents and robots [1][3] Group 1: Technology and Innovation - DeepMind CEO Demis Hassabis highlighted Genie 2's ability to create dynamic environments that simulate real-world physical properties, making it suitable for both entertainment and efficient robot training [3][6] - The model aims to build an understanding of the real world, offering a low-cost and high-efficiency solution for robot training, overcoming the limitations of traditional data collection methods [3][6] Group 2: Applications and Future Prospects - Genie 2 can generate nearly unlimited data in a simulated environment, allowing robots to learn initially in a virtual world before fine-tuning with minimal real-world data [3][6] - Future versions of the Genie model are expected to create more diverse and complex virtual worlds, supporting robots in learning new skills and interacting with humans and objects [6]
