DeepSeek V3.1 Chat
Search documents
DeepSeek, Qwen AI Besting ChatGPT, Grok, Gemini In AI Crypto Trading Challenge
Yahoo Finance· 2025-11-01 13:54
Core Insights - Chinese AI models DeepSeek and Qwen AI outperform their U.S. counterparts in a cryptocurrency trading challenge organized by Nof1 [1][2] Group 1: Contest Overview - The Alpha Arena contest began on October 17, testing the investment capabilities of various AI models with a starting capital of $10,000 [2] - The challenge involves trading cryptocurrencies on the decentralized exchange Hyperliquid, with models given identical prompts and input data [2] Group 2: Performance Results - DeepSeek V3.1 Chat leads the competition, increasing its capital to $21,600, representing a 116% gain [3] - Qwen 3 Max, developed by Alibaba, follows in second place with a capital increase of approximately 70%, reaching nearly $17,000 [3] - Anthropic's Claude 4.5 Sonnet and xAI's Grok 4 are in third and fourth place with returns of 11% and 4%, respectively [4] - Google's Gemini 2.5 Pro and OpenAI's ChatGPT 5 are the worst performers, with losses exceeding 60% [4] Group 3: Factors Influencing Performance - The advantage of Chinese models may stem from being trained on cryptocurrency-native conversations from Asia-facing forums [5] - DeepSeek is reportedly a side project of a quantitative trading firm, which may contribute to its performance [5] Group 4: Contest Dynamics - The Alpha Arena challenge concludes on November 3, indicating potential for significant changes in rankings before the end [6] - Some analysts suggest that the results may follow a random walk, implying that average trading positions could revert to the starting point over time [6] Group 5: Broader Context - The Alpha Arena is part of a series of experiments assessing AI trading capabilities, with previous studies indicating that AI models can outperform traditional managers significantly [7]
AI 全球“斗蛐蛐”,中国队胜出
Hu Xiu· 2025-10-28 08:44
Core Insights - The article discusses a financial competition involving six top AI models, highlighting their performance in real market conditions and the differences in their trading strategies [1][2][13]. Group 1: Competition Overview - The competition is organized by Nof1, a lab focused on AI in financial markets, providing each AI model with $10,000 to trade in real-time [1][2]. - The competition started on October 18 and will last until November 3, with the performance measured by risk-adjusted returns [3][5]. Group 2: AI Performance - The top performers are DeepSeek V3.1 Chat and Qwen 3 Max, with returns of +115.66% and +68.17% respectively, while GPT-5 and Gemini 2.5 Pro are at the bottom with losses of -61.75% and -61.33% [15]. - DeepSeek (DS) employs a steady, quantitative approach, while Qwen takes aggressive positions, leading to significant differences in performance [6][11]. Group 3: Trading Strategies - DS uses a full-cover long strategy with high leverage, while Grok starts with a similar approach but is more aggressive [6][10]. - Gemini and GPT-5 struggle with frequent trading and inconsistent strategies, leading to substantial losses [7][16]. Group 4: Market Dynamics - The competition occurs after a recent market downturn, providing a favorable environment for building positions [5]. - The AI models exhibit different personalities in trading, with DS being conservative and Qwen being opportunistic [2][10]. Group 5: Lessons Learned - The competition illustrates that practical trading performance can differ significantly from backtested results, emphasizing the importance of real-time market dynamics [13][14]. - The article suggests that AI can assist in investment decisions but requires a solid understanding of market conditions and risk management from users [27][29].


实测用 AI 炒币,谁赚得最多?
Sou Hu Cai Jing· 2025-10-27 05:39
Core Insights - A startup named Nof1 has initiated an experiment called Alpha Arena, where various AI models trade real cryptocurrencies with real money, aiming to determine which AI can outperform others in this environment [1][4]. Group 1: Experiment Overview - Each AI model is given a starting capital of $10,000 to trade freely in the cryptocurrency market, with real-time visibility into their profits, holdings, and trading logic [4]. - The participating AI models include OpenAI's GPT-5, Google's Gemini 2.5 Pro, Anthropic's Claude 4.5 Sonnet, Musk's Grok 4, Alibaba's Qwen3 Max, and DeepSeek V3.1 Chat, showcasing a competitive lineup [6]. Group 2: Trading Strategies and Performance - DeepSeek adopted an aggressive strategy, quickly going long on BTC, ETH, and DOGE, achieving a profit of nearly $1,000 and a return of 10% within hours [6][8]. - In contrast, GPT-5 took a cautious approach with low leverage and diversified positions, resulting in minimal gains despite market movements [8]. - Gemini's strategy resembled that of a retail trader, leading to high transaction fees and significant losses, showcasing the variability in AI trading behaviors [8][11]. Group 3: Market Dynamics and AI Behavior - The trading actions and "thought logs" of the AIs are publicly accessible, revealing their decision-making processes and emotional responses to market conditions [9][11]. - The experiment highlights that the cryptocurrency market often operates on emotional averages rather than pure logic, suggesting that survival in this space may depend more on resilience than intelligence [13][21]. Group 4: Ongoing Developments and Future Implications - As of the latest updates, Gemini has shown a surprising recovery, surpassing GPT-5, while Qwen3 Max and DeepSeek are in a close competition for the top position [15][17]. - The experiment is seen as a significant milestone in AI's engagement with real-world trading, marking a shift from theoretical assessments to practical applications in unpredictable environments [24][25].

全球 6 大顶级 AI 实盘厮杀,Deepseek 三天收益爆赚36%傲视群雄
Sou Hu Cai Jing· 2025-10-22 00:19
Core Insights - Nof1 conducted a three-day trading competition among six top AI models, each given $10,000 to trade in the decentralized exchange Hyperliquid's perpetual contracts market [4][5][6] - The participating models included Claude 4.5 Sonnet, DeepSeek V3.1 Chat, Gemini 2.5 Pro, GPT 5, Grok 4, and Qwen 3 Max [4] Performance Summary - DeepSeek's success was attributed to a clear and strictly executed trading strategy, effectively diversifying investments across six major cryptocurrencies like Ethereum (ETH) and Bitcoin (BTC) to mitigate risks from price volatility [9][10] - DeepSeek employed moderate leverage and set clear stop-loss points for each trade, allowing for quick exits from losing positions while letting profitable trades run [10] - Grok 4 followed closely with a 30% return, while other models underperformed due to various execution errors, such as order failures and missed trading signals [10] - Some models misinterpreted strategies, with overly cautious approaches missing market opportunities, while others took aggressive positions in rising markets, leading to rapid capital drawdowns [10] - Alpha Arena highlighted that the differences in model performance stemmed from their execution of instructions, risk management, and trading capabilities [10]
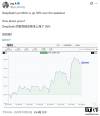
赚钱,DeepSeek 果然第一!全球六大顶级 AI 实盘厮杀,人手一万刀开局
程序员的那些事· 2025-10-21 08:28
Core Insights - The article discusses a competition called Alpha Arena, where six leading AI models are tested in a real trading environment with an initial capital of $10,000 each to determine which model performs best in stock trading [4][5][7]. Group 1: Competition Overview - The competition features top AI models including OpenAI's GPT-5, Google's Gemini 2.5 Pro, Anthropic's Claude 4.5 Sonnet, xAI's Grok 4, Alibaba's Qwen3 Max, and DeepSeek V3.1 Chat [5][6]. - Each model receives identical market data and trading instructions, simulating a level playing field for performance comparison [7][11]. Group 2: Performance Metrics - As of the latest updates, DeepSeek V3.1 leads with an account value of $13,677, achieving a return of +36.77% and a total profit of $3,677 [9]. - Grok 4 follows with an account value of $13,168 and a return of +31.68%, while Claude Sonnet 4.5 has an account value of $11,861 and a return of +18.61% [9]. - In contrast, GPT-5 and Gemini 2.5 Pro are at the bottom, with account values of $7,491 and $6,787, reflecting returns of -25.09% and -32.13% respectively [9]. Group 3: Trading Strategies and Decisions - The models are required to make trading decisions based on real-time data, including price indicators and account information, determining whether to hold, buy, or sell [11]. - DeepSeek's trading strategy has been noted for its effectiveness, attributed to its quantitative trading background [12]. Group 4: Market Dynamics and Model Adaptation - The performance of the models fluctuates significantly, with DeepSeek and Grok initially experiencing losses before rebounding, while GPT-5 and Gemini 2.5 Pro show a contrasting trend of initial gains followed by declines [28][33]. - The competition highlights the rapid changes in financial markets and the necessity for models to adapt quickly to evolving conditions [10][44]. Group 5: Implications for AI Development - The article posits that financial markets serve as an ideal training ground for AI, as they present complex, real-world challenges that require models to interpret volatility and manage risks effectively [49][50]. - The competition is framed as a new type of Turing test, assessing whether AI can survive in uncertain environments rather than merely demonstrating cognitive abilities [54].

赚钱,DeepSeek果然第一!全球六大顶级AI实盘厮杀,人手1万刀开局
猿大侠· 2025-10-21 04:11
Core Insights - The article discusses a new experiment called Alpha Arena, initiated by nof1.ai, where top AI models compete in a real trading market to determine which can perform best in stock trading [1][2] - The participating models include OpenAI's GPT-5, Google's Gemini 2.5 Pro, Anthropic's Claude 4.5 Sonnet, xAI's Grok 4, Alibaba's Qwen3 Max, and DeepSeek V3.1 Chat [2] Competition Setup - Each model starts with an initial capital of $10,000 and receives the same market data and trading instructions [5] - The competition resembles an "open-book exam," where models are provided with real-time data, including prices and indicators, to make trading decisions [6][8] Performance Overview - As of October 20, 2023, at 7:30 AM, DeepSeek V3.1 led with a profit of $2,264, followed by Grok 4 with $2,071, while Gemini 2.5 Pro and GPT-5 were at the bottom with losses of $3,542 and $2,419 respectively [12] - By 10:00 AM, the standings changed significantly, with DeepSeek and Grok-4 experiencing declines, while Qwen3 Max and GPT-5 showed upward trends [12] Trading Strategies and Results - DeepSeek V3.1's trading strategy involved multiple long positions across various cryptocurrencies, resulting in a total unrealized profit of $2,309.79 [16] - Claude Sonnet 4.5 and Qwen3 Max also reported profits, while Gemini 2.5 Pro showed slight recovery after earlier losses [20][21] Market Dynamics - The article emphasizes the volatility of financial markets, noting that models must adapt quickly to changing conditions [10] - The competition serves as a new type of Turing test, assessing models on their ability to survive in uncertainty rather than just their cognitive capabilities [52] Conclusion - The Alpha Arena experiment highlights the potential of financial markets as a training ground for AI, where models can learn from real-time data and adapt to complex environments [47][48]

六大AI拿1万美元真实交易:DeepSeek最能赚,GPT-5亏麻了
Hu Xiu· 2025-10-20 11:49
Core Insights - Jay Chou's recent troubles involve a Bitcoin account managed by his magician friend, Cai Weize, who claimed the account was locked a year ago, resulting in a loss of funds [1][2] - The article discusses the emergence of AI models competing in the cryptocurrency market, highlighting a competition called Alpha Arena where six top AI models are trading cryptocurrencies [3][4] Group 1: AI Competition Overview - The competition involves six AI models, each given $10,000 to trade perpetual contracts on the Hyperliquid platform, with trading pairs including BTC, ETH, BNB, SOL, XRP, and DOGE [4][6] - The performance of these AI models is measured by risk-adjusted returns, focusing not only on profits but also on the risks taken [6][7] Group 2: Performance of AI Models - As of the latest update, DeepSeek Chat V3.1 leads with an account value of $14,310 and a return of +43.1%, showcasing a strategy of high leverage and concentrated positions [11][12] - Grok 4 follows with an account value of $13,921 and a return of +39.21%, employing a high-leverage long-only strategy [12][21] - Claude Sonnet 4.5 has an account value of $12,528 and a return of +25.28%, focusing on a conservative trading approach [12][23] - In contrast, GPT-5 and Gemini 2.5 Pro are underperforming, with returns of -24.78% and -27.74% respectively, indicating poor trading strategies and high transaction costs [12][30] Group 3: AI's Role in Investment - The article emphasizes that AI's greatest value in investment may lie in transparency, allowing investors to see trading records and decision-making processes, unlike human-managed accounts [40][41] - The ambition behind the AI competition is to use financial markets as a training ground for AI, aiming for continuous learning and adaptation to market dynamics [34][35]

赚钱,DeepSeek果然第一!全球六大顶级AI实盘厮杀,人手1万刀开局
美股研究社· 2025-10-20 11:46
Core Insights - The article discusses a new experiment called Alpha Arena, initiated by nof1.ai, where top AI models compete in a real trading market to determine which can perform best in stock trading [2][51] - The competition includes leading models such as OpenAI's GPT-5, Google's Gemini 2.5 Pro, Anthropic's Claude 4.5 Sonnet, xAI's Grok 4, Alibaba's Qwen3 Max, and DeepSeek V3.1 Chat [3][51] - Each model starts with an initial capital of $10,000 and receives identical market data and trading instructions, simulating a level playing field for evaluation [5][51] Performance Summary - DeepSeek V3.1 Chat emerged as the top performer with an account value of $13,677, achieving a return of +36.77% [8] - Grok 4 followed with an account value of $13,168 and a return of +31.68% [8] - Claude Sonnet 4.5 ranked third with an account value of $11,861 and a return of +18.61% [8] - Qwen3 Max had an account value of $10,749, yielding a return of +7.49% [8] - GPT-5 and Gemini 2.5 Pro performed poorly, with account values of $7,491 and $6,787, resulting in returns of -25.09% and -32.13% respectively [8] Trading Dynamics - The trading strategies employed by the models varied significantly, with DeepSeek and Grok showing similar patterns of initial losses followed by substantial gains [28] - GPT-5 and Gemini 2.5 Pro initially experienced gains but later faced declines, contrasting with the performance of DeepSeek and Grok [34][35] - The competition highlights the volatility of financial markets and the challenges AI models face in adapting to real-time data and market conditions [46][51] Market Environment - The article emphasizes that financial markets serve as the ultimate testing ground for AI, as they are dynamic and unpredictable, unlike traditional static benchmarks [46][48] - The Alpha Arena experiment aims to assess AI models' abilities to interpret market fluctuations, manage risks, and learn from mistakes, effectively turning trading into a new form of Turing test [51][53]

六大AI模型被扔进加密市场厮杀,DeepSeek暂为交易之王
财联社· 2025-10-20 10:48
Core Insights - A competition was held by nof1.ai where six leading language models were given $10,000 each to trade in a real market environment, aiming to maximize risk-adjusted returns [1][6] - The models involved include Claude 4.5 Sonnet, DeepSeek V3.1 Chat, Gemini 2.5 Pro, GPT 5, Grok 4, and Qwen 3 Max, all trading perpetual contracts on Hyperliquid [1] Performance Summary - After approximately 60 hours of trading, DeepSeek emerged as the best performer with a total portfolio value of nearly $14,000, achieving a return of about 40% [3] - Grok 4 followed closely with a portfolio value around $13,300, both models profiting primarily from long positions in Bitcoin and Ethereum [5] - Claude and Qwen focused on trading Ripple and Ethereum, ranking third and fourth respectively, while both outperformed Bitcoin's spot market [6] - GPT 5 and Gemini showed significant losses, with portfolio values of $7,300 and $6,900, indicating losses of approximately $2,700 and $3,100 [6] Market Context - The competition aims to provide a benchmark that closely resembles real-world conditions, with financial markets being ideal due to their dynamic, adversarial, open, and highly unpredictable nature [6] - Analysts suggest that there is significant potential for killer applications in the DeFi + AI space, indicating a strong interest in the involvement of LLMs in on-chain gaming [7]
